Rows: 173
Columns: 21
$ Rank <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15…
$ Major_code <dbl> 2419, 2416, 2415, 2417, 2405, 2418, 6202, 5001, 2…
$ Major <chr> "PETROLEUM ENGINEERING", "MINING AND MINERAL ENGI…
$ Total <dbl> 2339, 756, 856, 1258, 32260, 2573, 3777, 1792, 91…
$ Men <dbl> 2057, 679, 725, 1123, 21239, 2200, 2110, 832, 803…
$ Women <dbl> 282, 77, 131, 135, 11021, 373, 1667, 960, 10907, …
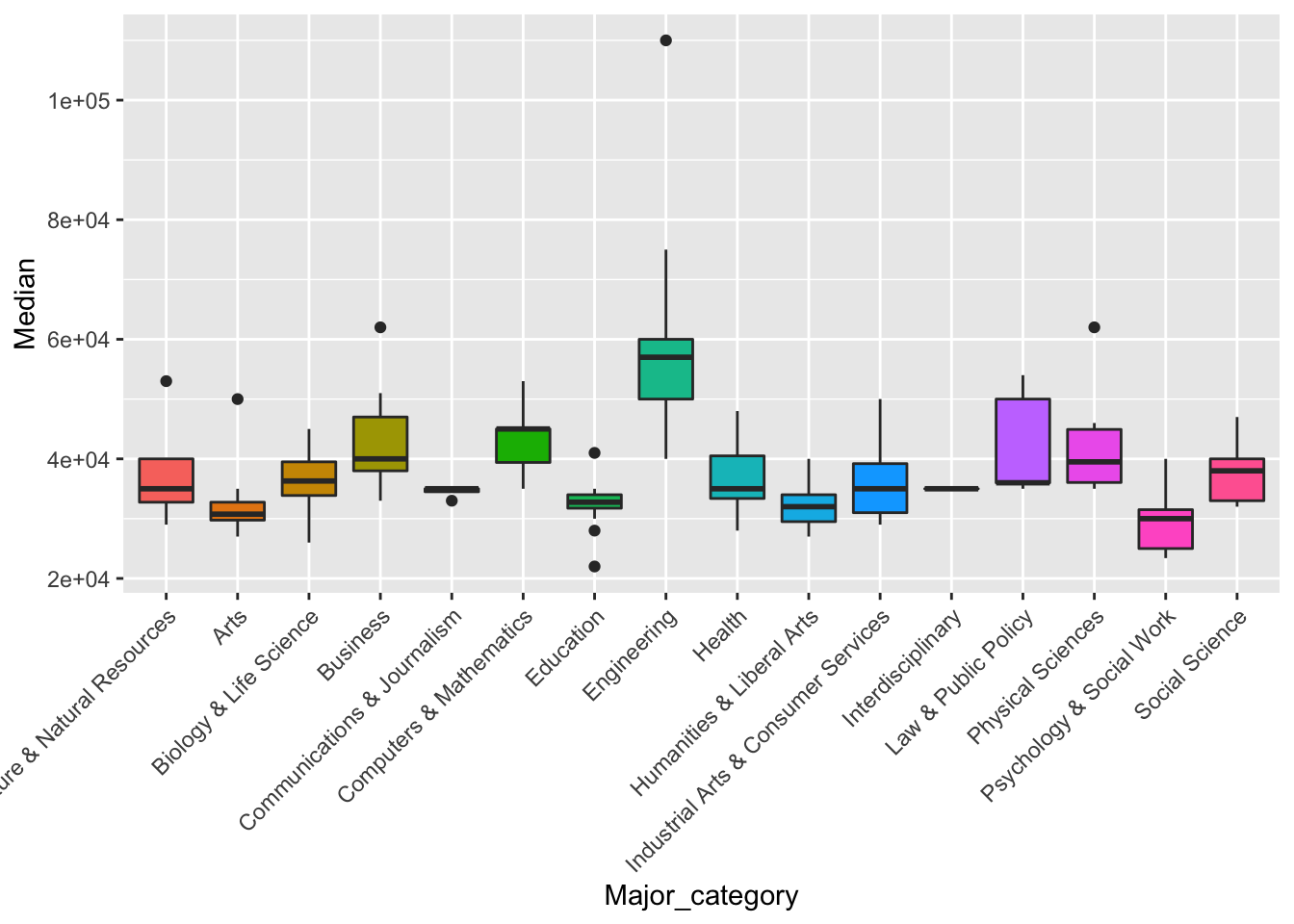
$ Major_category <chr> "Engineering", "Engineering", "Engineering", "Eng…
$ ShareWomen <dbl> 0.1205643, 0.1018519, 0.1530374, 0.1073132, 0.341…
$ Sample_size <dbl> 36, 7, 3, 16, 289, 17, 51, 10, 1029, 631, 399, 14…
$ Employed <dbl> 1976, 640, 648, 758, 25694, 1857, 2912, 1526, 764…
$ Full_time <dbl> 1849, 556, 558, 1069, 23170, 2038, 2924, 1085, 71…
$ Part_time <dbl> 270, 170, 133, 150, 5180, 264, 296, 553, 13101, 1…
$ Full_time_year_round <dbl> 1207, 388, 340, 692, 16697, 1449, 2482, 827, 5463…
$ Unemployed <dbl> 37, 85, 16, 40, 1672, 400, 308, 33, 4650, 3895, 2…
$ Unemployment_rate <dbl> 0.018380527, 0.117241379, 0.024096386, 0.05012531…
$ Median <dbl> 110000, 75000, 73000, 70000, 65000, 65000, 62000,…
$ P25th <dbl> 95000, 55000, 50000, 43000, 50000, 50000, 53000, …
$ P75th <dbl> 125000, 90000, 105000, 80000, 75000, 102000, 7200…
$ College_jobs <dbl> 1534, 350, 456, 529, 18314, 1142, 1768, 972, 5284…
$ Non_college_jobs <dbl> 364, 257, 176, 102, 4440, 657, 314, 500, 16384, 1…
$ Low_wage_jobs <dbl> 193, 50, 0, 0, 972, 244, 259, 220, 3253, 3170, 98…