Recall: Two Big Problems with Data
- We use econometrics to identify causal relationships & make inferences about them:
- Problem for identification: endogeneity
- \(X\) is exogenous if \(cor(x, u) = 0\)
- \(X\) is endogenous if \(cor(x, u) \neq 0\)
- Problem for inference: randomness
- Data is random due to natural sampling variation
- Taking one sample of a population will yield slightly different information than another sample of the same population


Why Sample vs. Population Matters
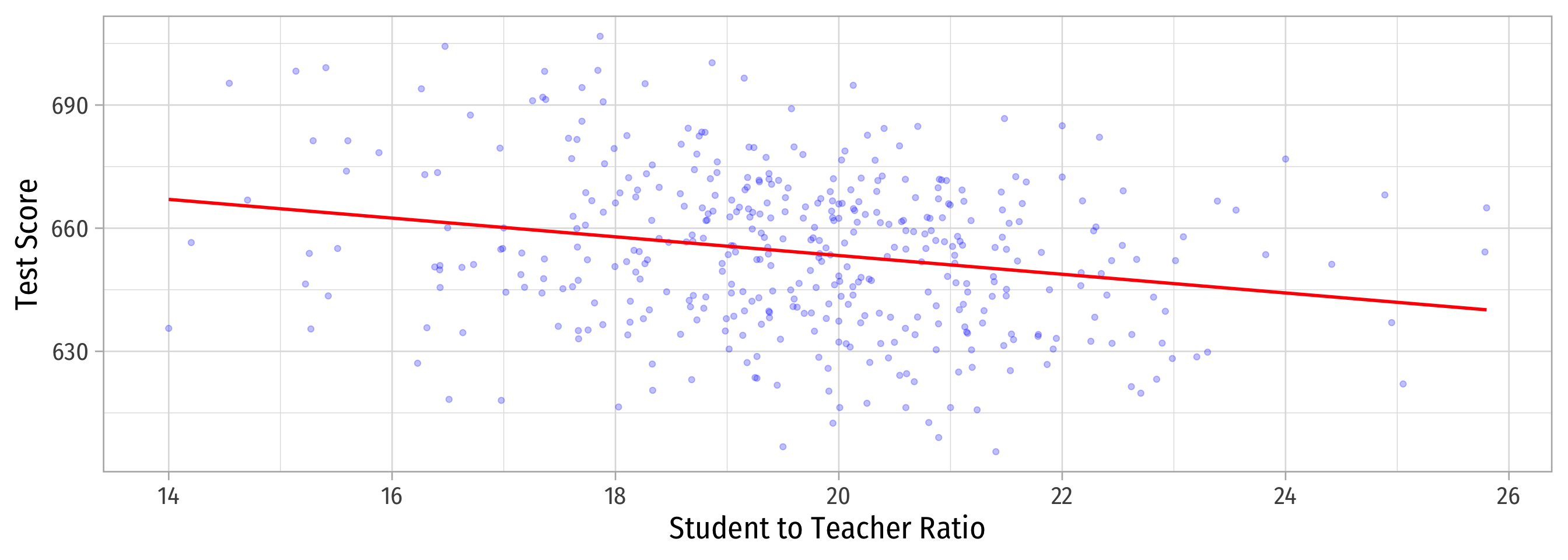
Population relationship
\(Y_i = 698.93 + -2.28 X_i + u_i\)
\(Y_i = \beta_0 + \beta_1 X_i + u_i\)
Why Sample vs. Population Matters
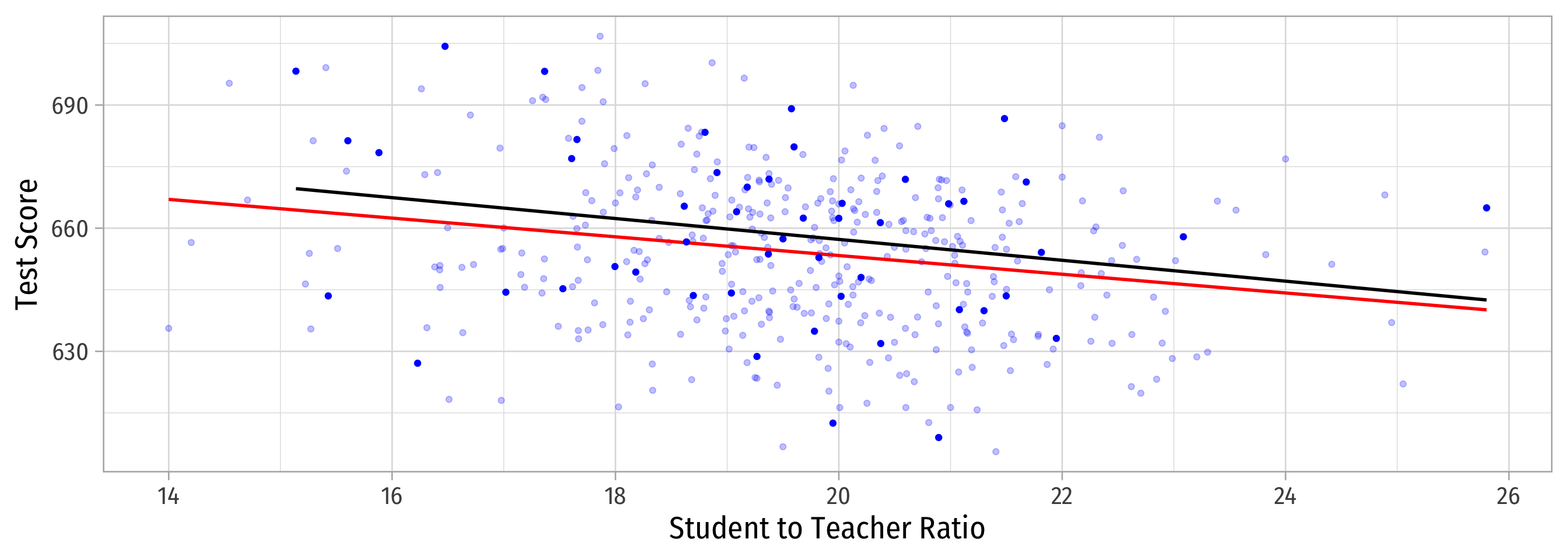
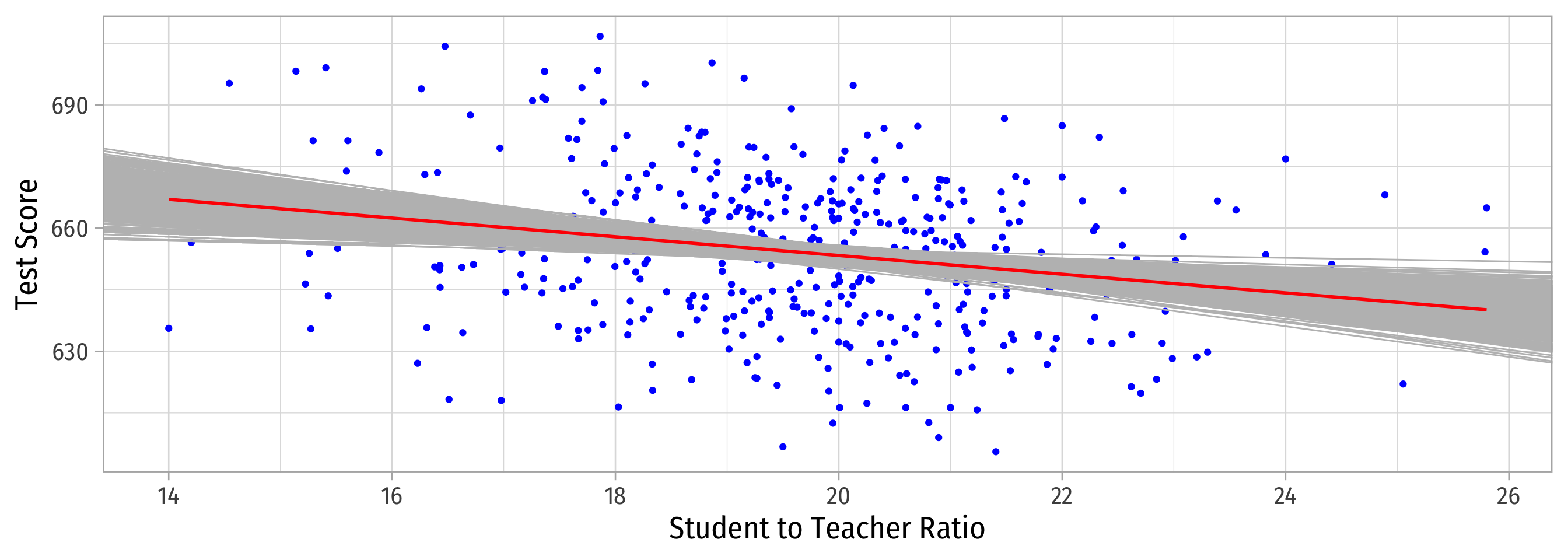
Sample 1: 50 random observations
Population relationship
\(Y_i = 698.93 + -2.28 X_i + u_i\)
Sample relationship
\(\hat{Y}_i = 708.12 + -2.54 X_i\)
Why Sample vs. Population Matters
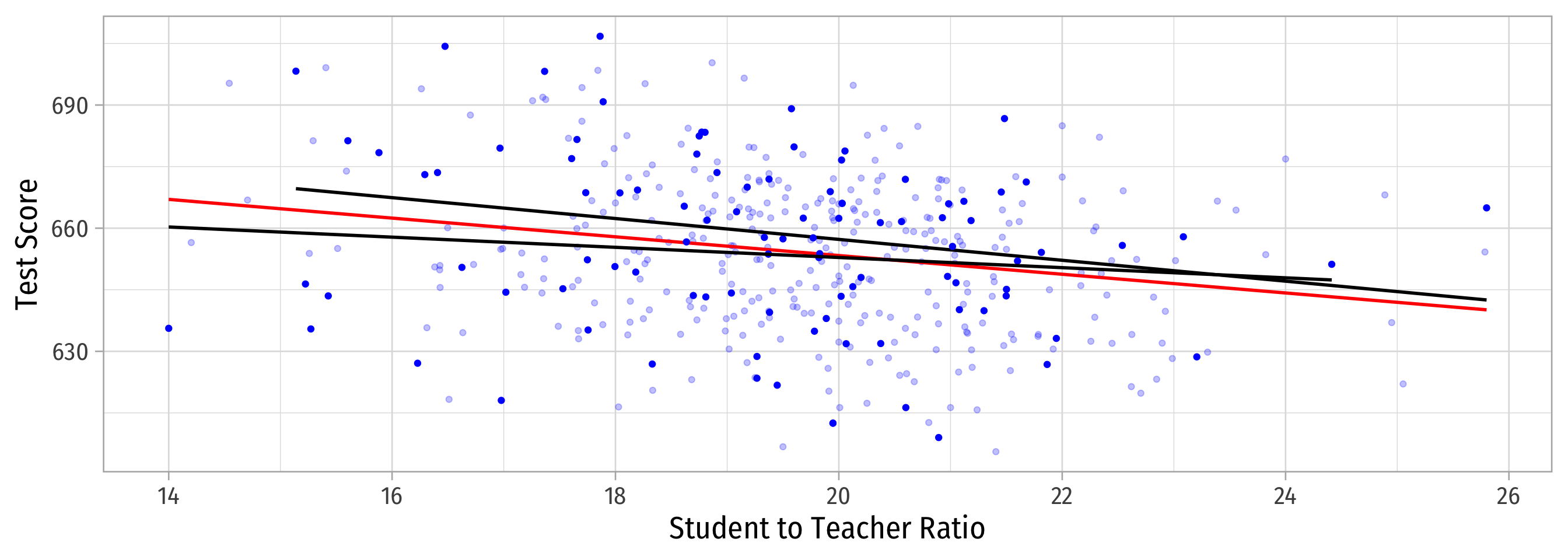
Sample 2: 50 random individuals
Population relationship
\(Y_i = 698.93 + -2.28 X_i + u_i\)
Sample relationship
\(\hat{Y}_i = 708.12 + -2.54 X_i\)
Why Sample vs. Population Matters
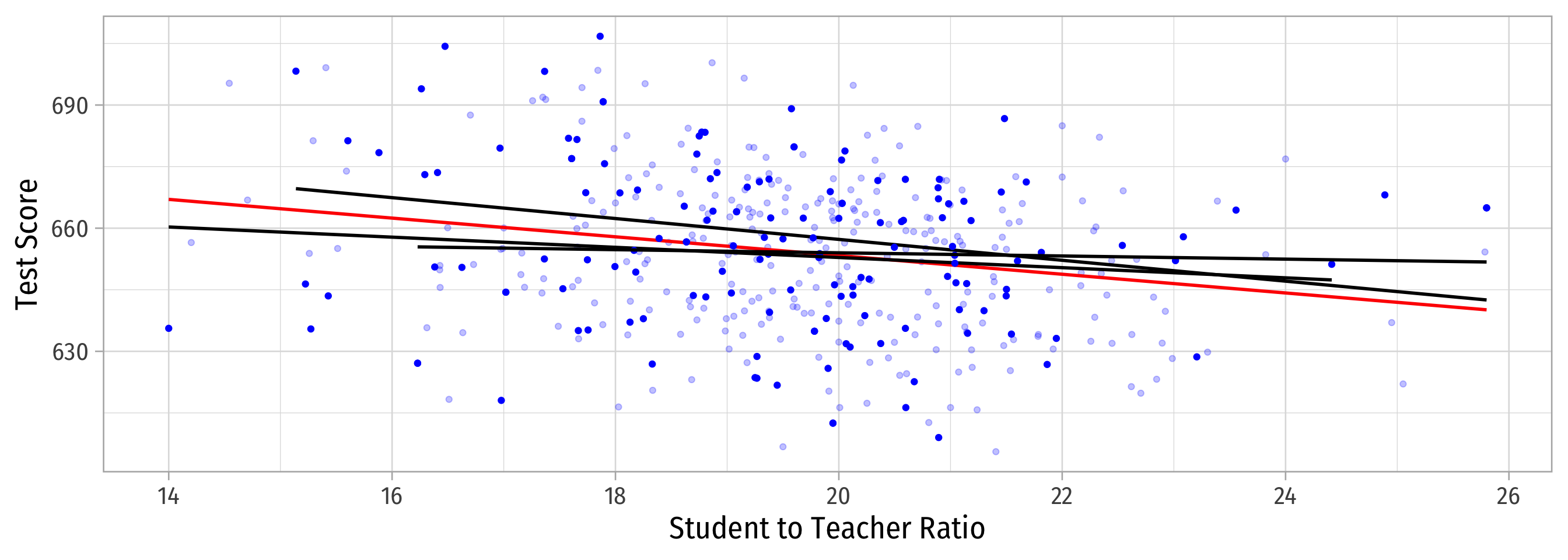
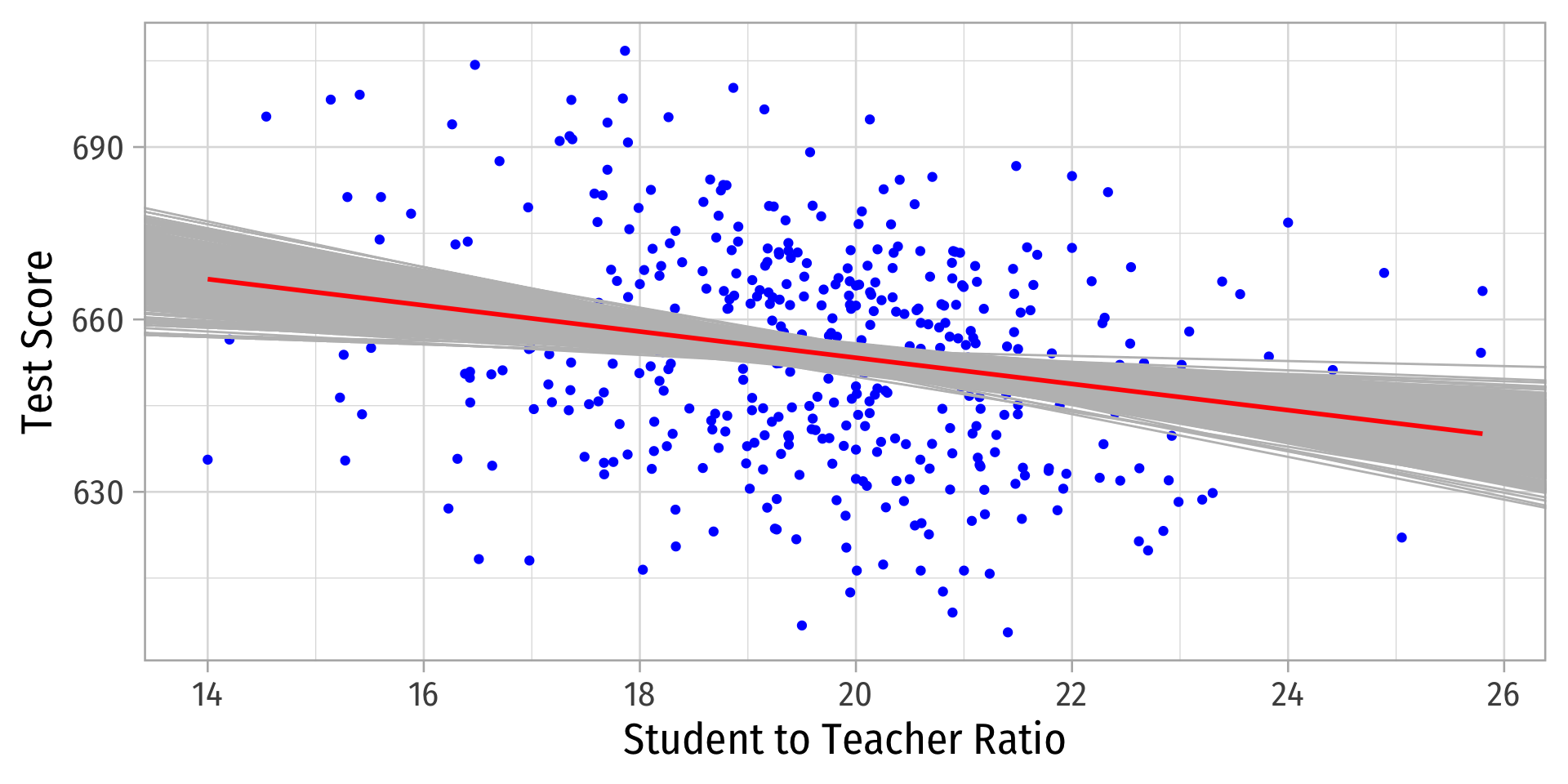
Sample 3: 50 random individuals
Population relationship
\(Y_i = 698.93 + -2.28 X_i + u_i\)
Sample relationship
\(\hat{Y}_i = 708.12 + -2.54 X_i\)
Why Sample vs. Population Matters
Let’s repeat this process 10,000 times!
This exercise is called a (Monte Carlo) simulation
- I’ll show you how to do this next class with the
inferpackage
- I’ll show you how to do this next class with the
Why Sample vs. Population Matters
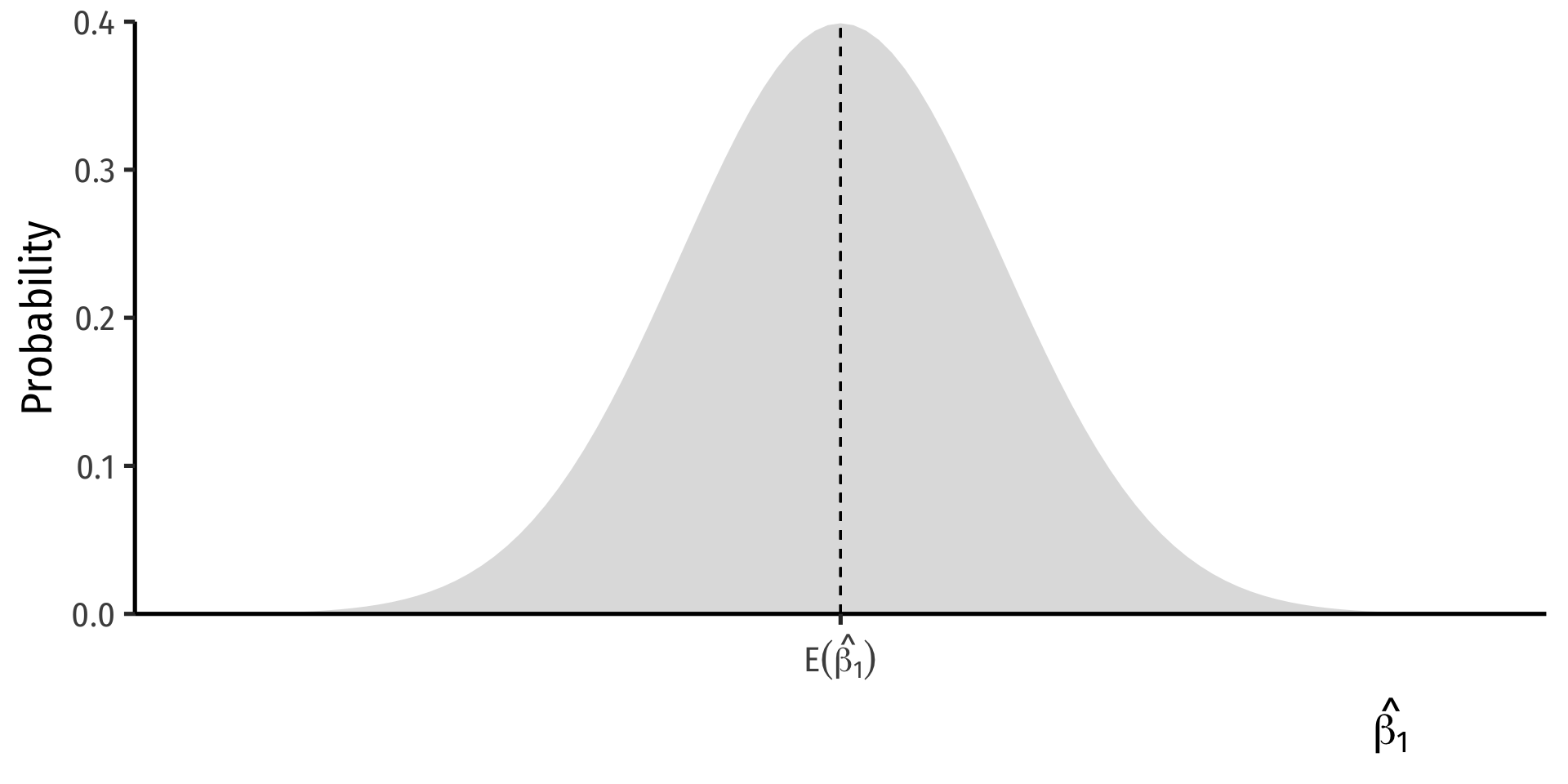
- On average, estimated regression lines from (hypothetical) samples provide an unbiased estimate of true population regression line
\[\mathbb{E}[\hat{\beta}_1] = \beta_1\]
But, any individual estimate can miss the mark
This leads to uncertainty about our estimated regression line
- We only have 1 sample in reality!
- This is why we care about the standard error of our line: \(se(\hat{\beta_1})\)!
Estimation and Statistical Inference
Our problem with uncertainty is we don’t know whether our sample estimate is close or far from the unknown population parameter
But we can use our errors to learn how well our model statistics likely estimate the true parameters
Use \(\hat{\beta_1}\) and its standard error, \(se(\hat{\beta_1})\) for statistical inference about true \(\beta_1\)
We have two options…
Estimation and Statistical Inference

- Use our \(\hat{\beta_1}\) & \(se(\hat{\beta_1})\) to determine if statistically significant evidence to reject a hypothesized \(\beta_1\)

- Use our \(\hat{\beta_1}\) & \(se(\hat{\beta_1})\) to create a range of values that gives us a good chance of capturing the true \(\beta_1\)
Accuracy vs. Precision

Generating Confidence Intervals
- We can generate our confidence interval by generating a “bootstrap” sampling distribution:
- Take our sample data and resample it many times by selecting random observations and then replacing them
- This allows us to approximate the sampling distribution of \(\hat{\beta_1}\) by simulation!

Confidence Intervals Using the infer Package I
Confidence Intervals Using the infer Package II

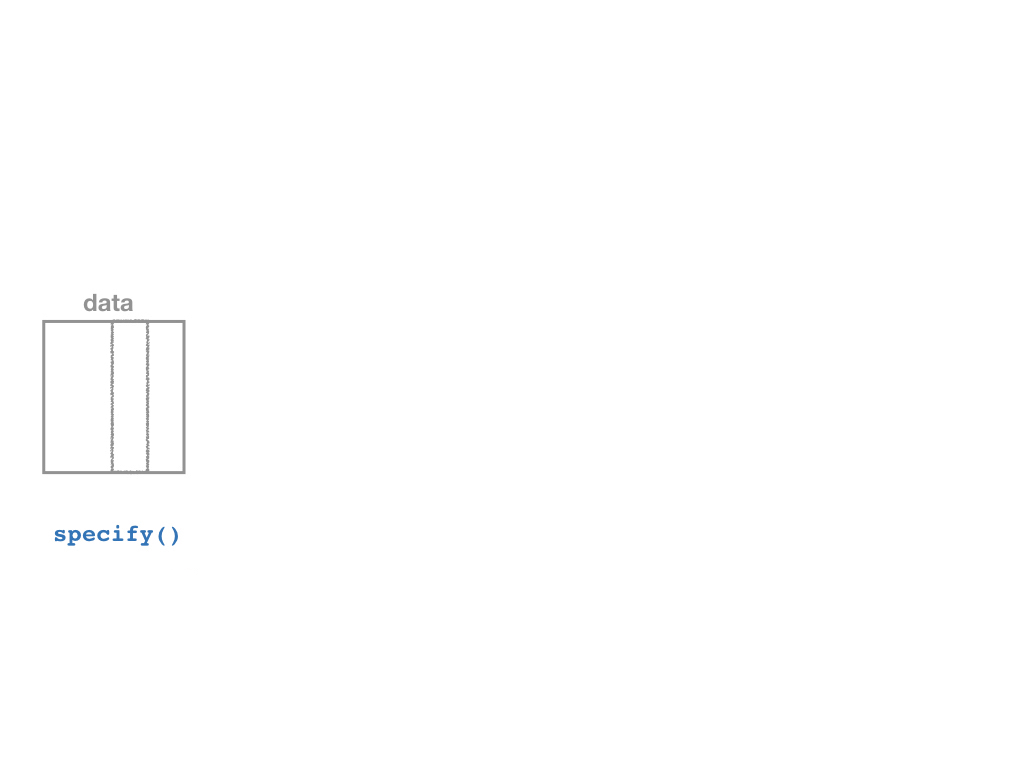
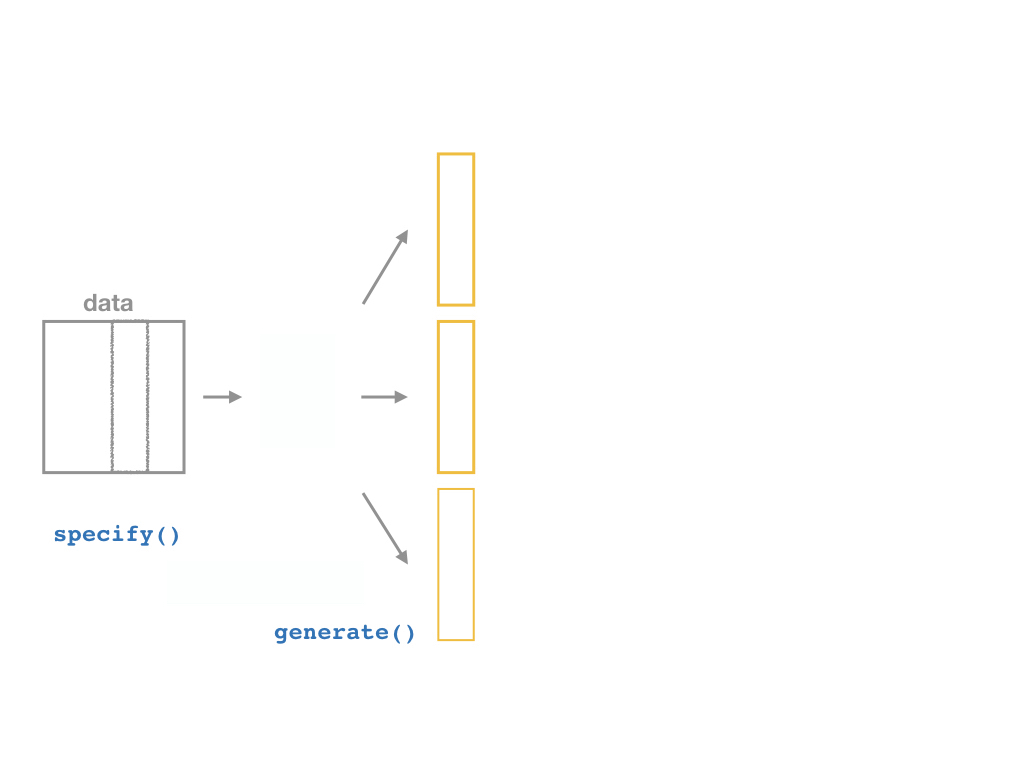
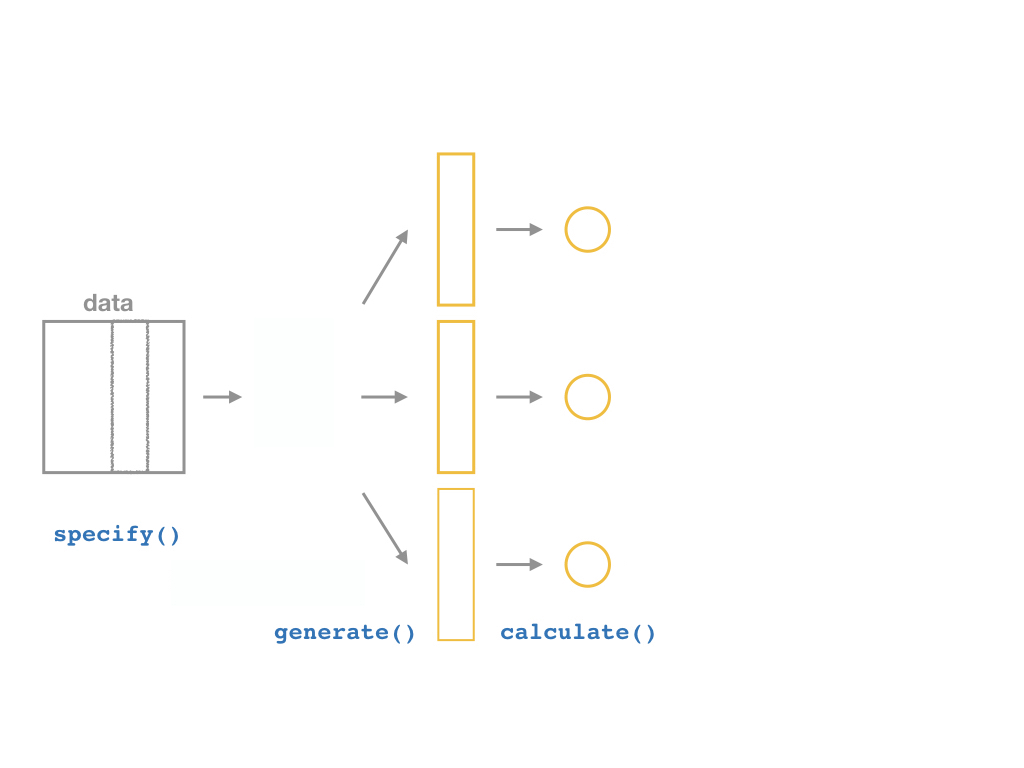
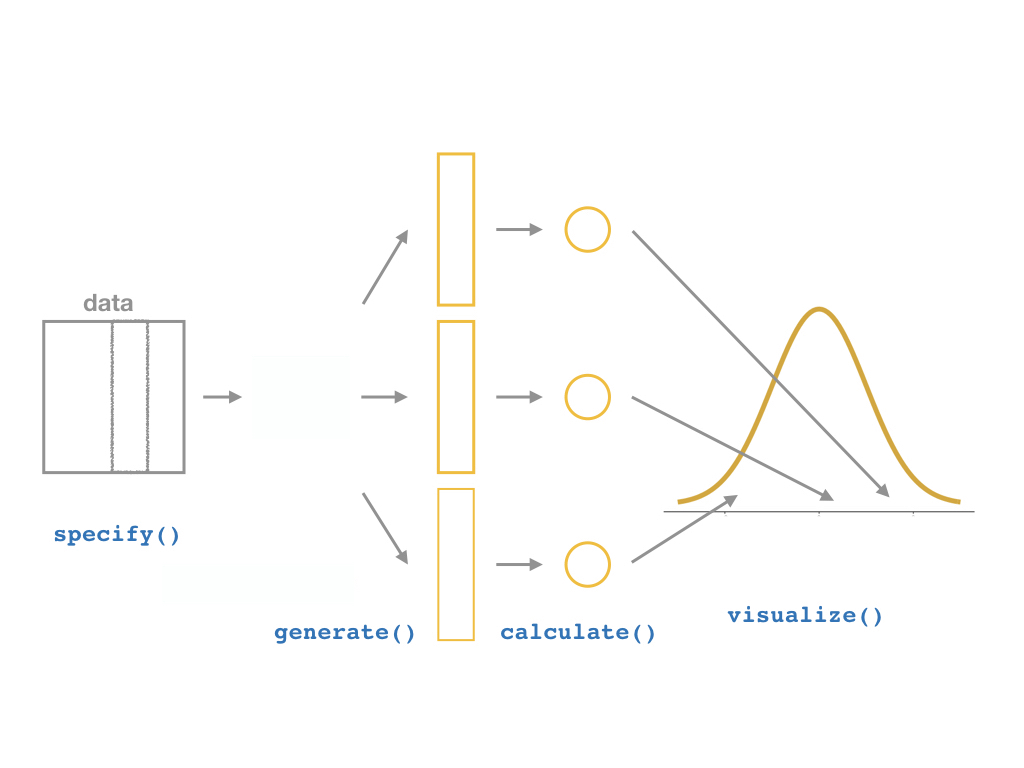
inferallows you to run through these steps manually to understand the process:
specify()a modelgenerate()a bootstrap distributioncalculate()the confidence intervalvisualize()with a histogram (optional)
Confidence Intervals Using the infer Package III
Confidence Intervals Using the infer Package III
Confidence Intervals Using the infer Package III
Confidence Intervals Using the infer Package III
Confidence Intervals Using the infer Package III
The infer Pipeline: specify()
The infer Pipeline: generate()
The infer Pipeline: calculate()
Confidence Interval
- A 95% confidence interval is the middle 95% of the sampling distribution
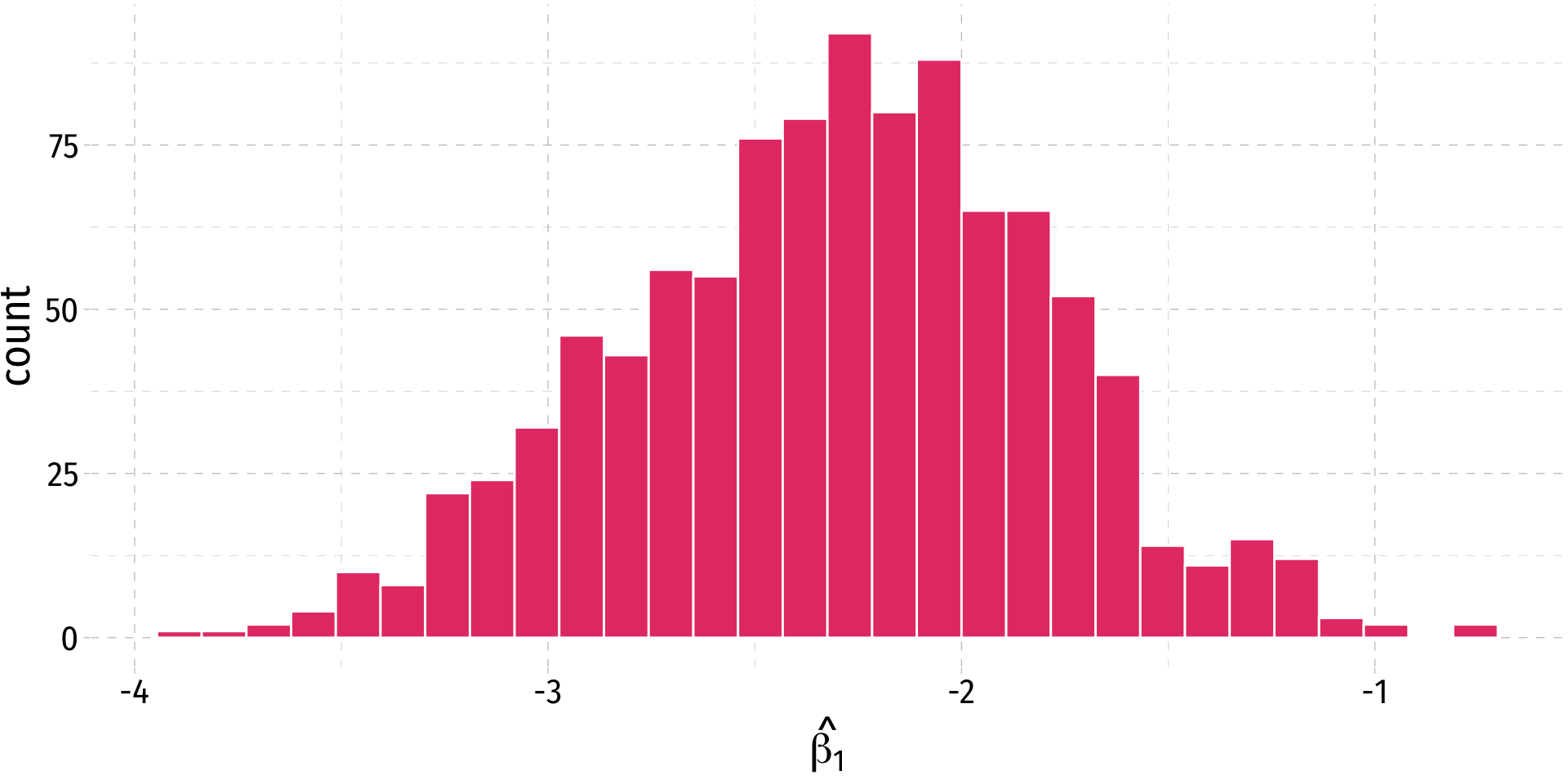
Confidence Interval
- A 95% confidence interval is the middle 95% of the sampling distribution
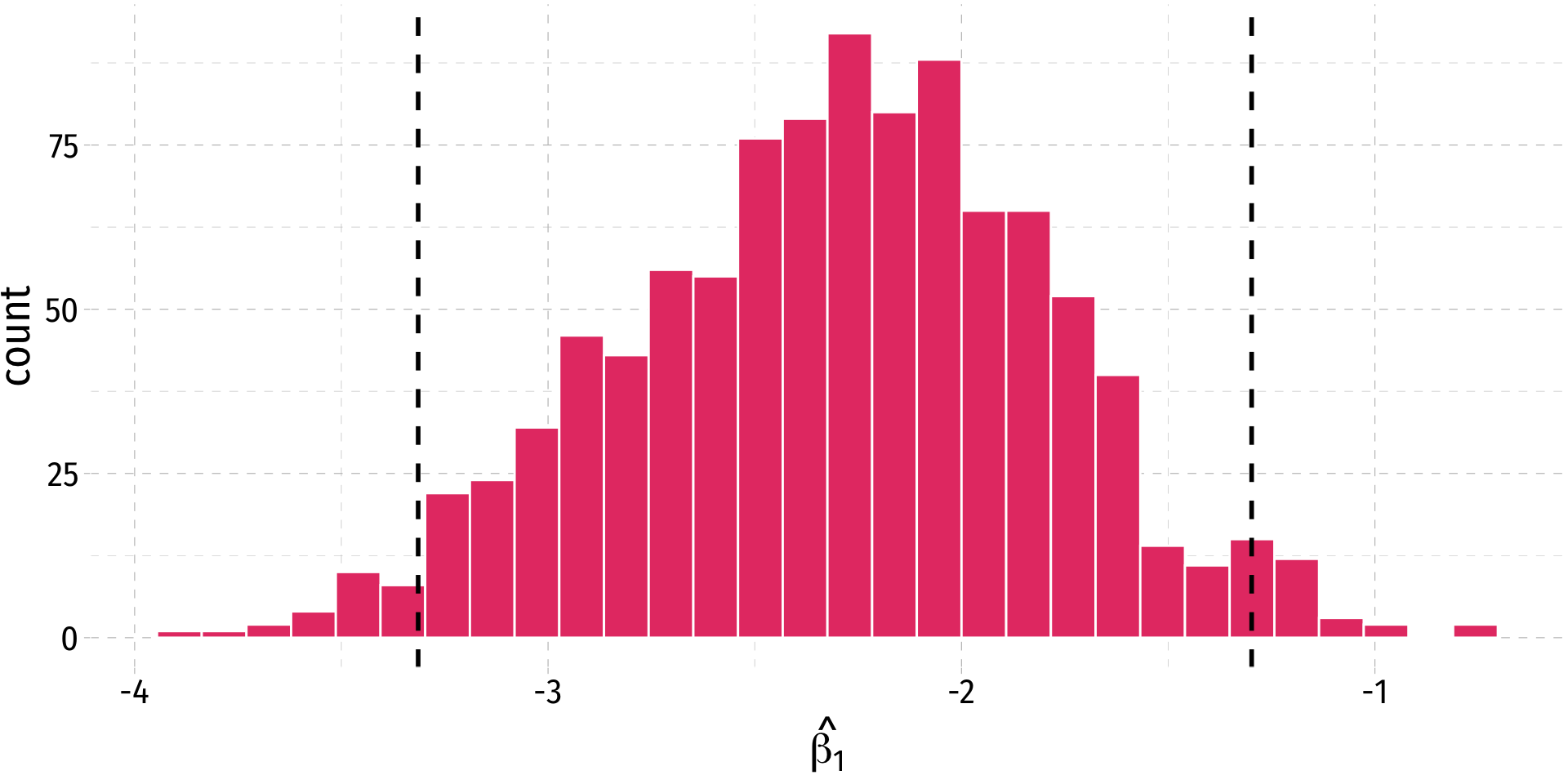
The infer Pipeline: visualize()

The infer Pipeline: visualize()
Specify
Generate
Calculate
Visualize
%>% visualize()

Confidence Intervals, Theory
- In general, a confidence interval (CI) takes a point estimate and extrapolates it within some margin of error (MOE):
\(\bigg( \big[\) estimate - MOE \(\big]\), \(\big[\) estimate + MOE \(\big] \bigg)\)
- The main question is, how confident do we want to be that our interval contains the true parameter?
- Larger confidence level, larger margin of error (and thus larger interval)
Confidence Intervals, Theory
- \(\color{#6A5ACD}{(1- \alpha)}\) is the confidence level of our confidence interval
- \(\color{#6A5ACD}{\alpha}\) is the “significance level” that we use in hypothesis testing
- \(\color{#6A5ACD}{\alpha}=\) probability that the true parameter is not contained within our interval
- Typical levels: 90%, 95%, 99%
- 95% is especially common, \(\alpha=0.05\)
Confidence Levels
Depending on our confidence level, we are essentially looking for the middle \((1-\alpha)\)% of the sampling distribution
This puts \(\alpha\) in the tails; \(\frac{\alpha}{2}\) in each tail
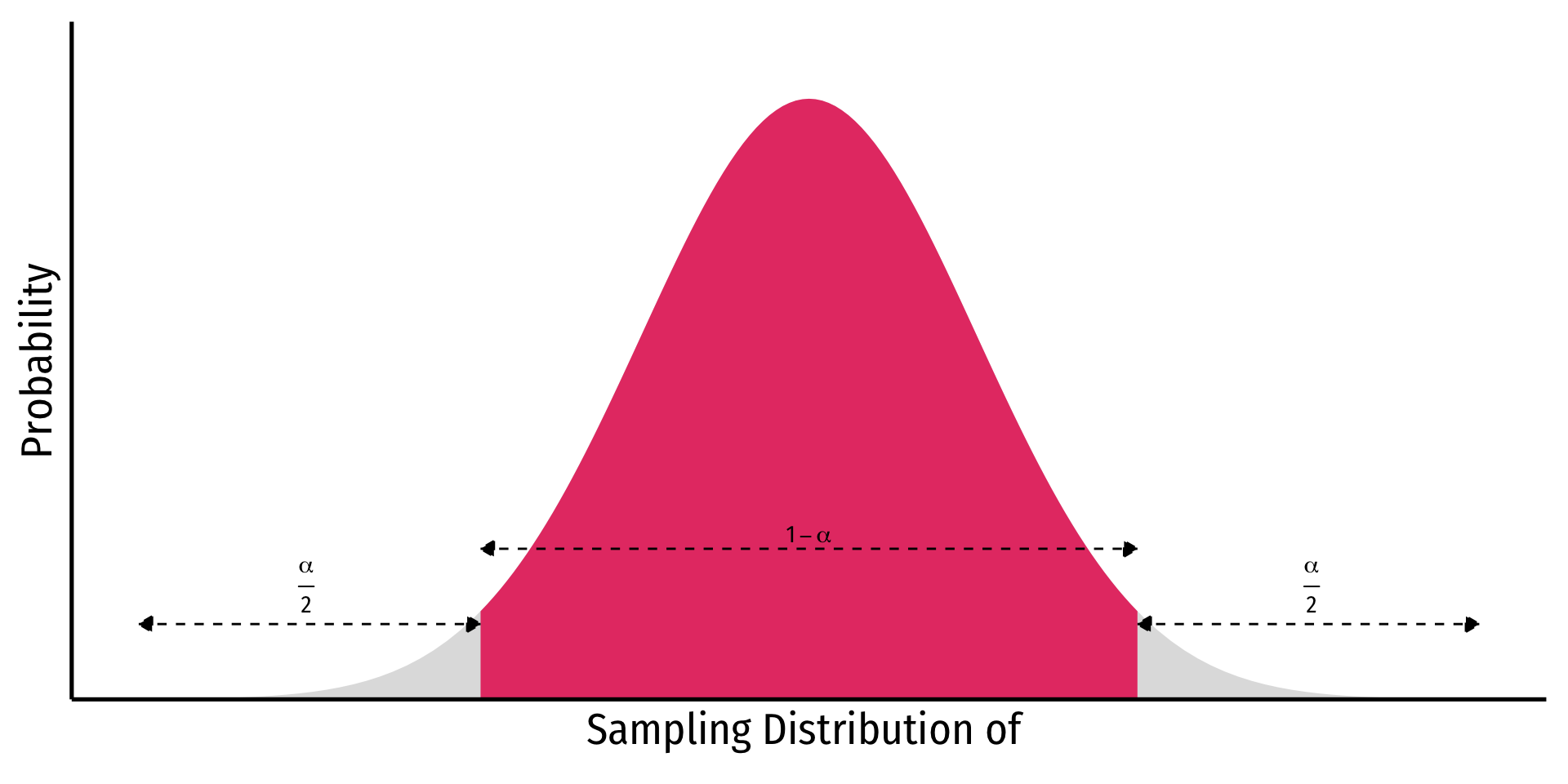
Confidence Levels and the Empirical Rule
Recall the 68-95-99.7% empirical rule for (standard) normal distributions!1
95% of data falls within 2 standard deviations of the mean
Thus, in 95% of samples, the true parameter is likely to fall within about 2 standard deviations of the sample estimate
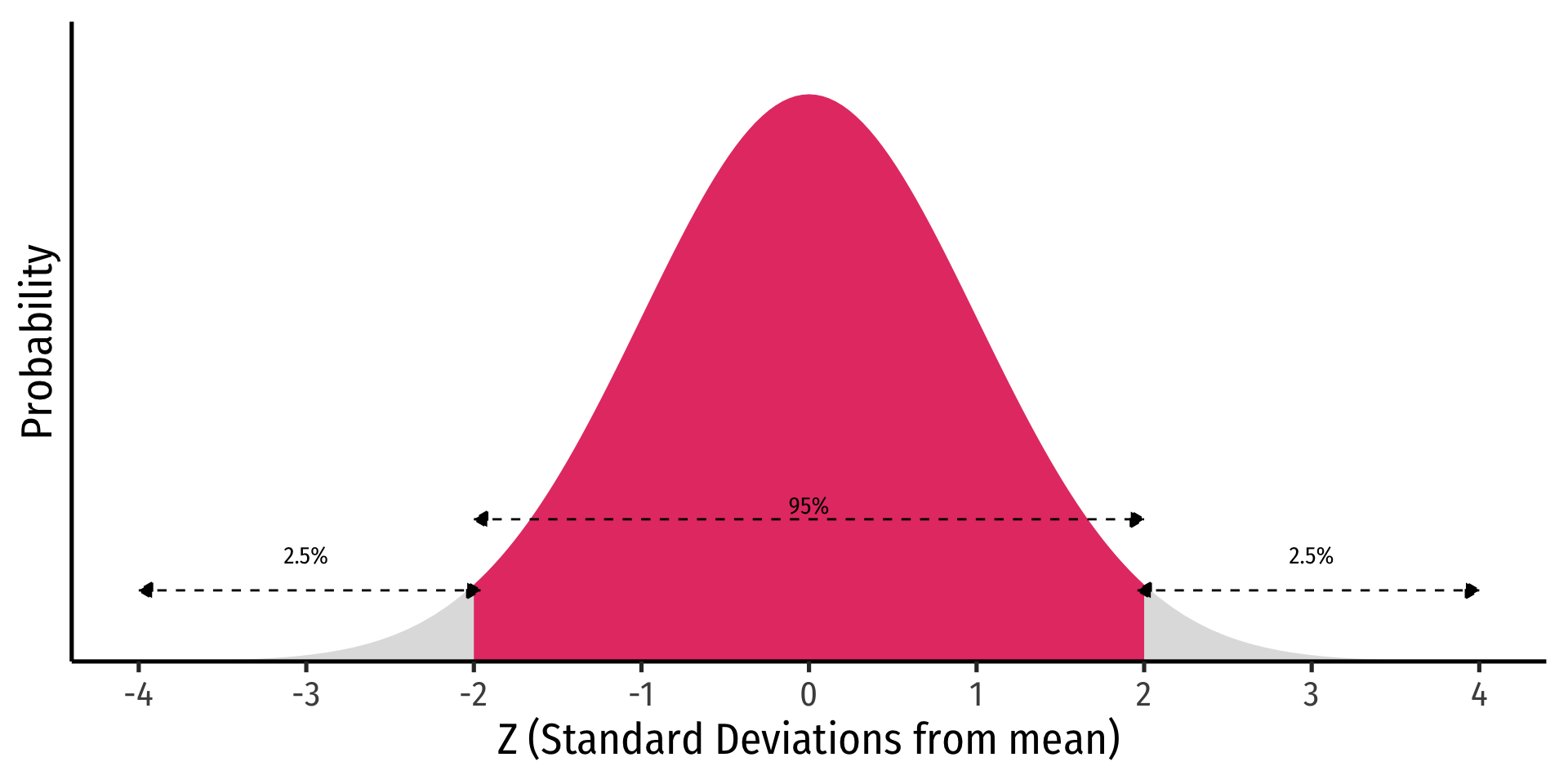
Estimating with broom
broom’stidy()command can include confidence intervals
